Unit Test & TDD Lambda Functions
28 Feb 2018Note: This is the third post in a series on production-ready AWS Lamdba
I’ve had the chance to use Lambda functions at two of my previous clients. With a low cost of getting started, Lambda has been useful for building and testing new ideas, and has proven mature enough for production.
Notably absent from my experience so far, though, was automated testing. I wanted to find a way to test Lambda functions while developing them - preferably, in a test environment that would not make live calls to AWS, and allow me to test the behaviour of a given function at a high level.
In researching this topic, I came across a few approaches, most notably placebo, discussed in this post, and moto. Placebo acts as a request-recorder of sorts - it will allow you to record calls to AWS and then play them back later. Moto’s approach is to mock out AWS services entirely, in a stateful way. Your code still can make calls to create and alter resources, and it will appear as though these changes are actually being made. However, this is all happening in moto’s mocked services, not on AWS directly.
I think that moto’s approach is a lot more flexible. Using it, we can enable testing through state verification. If we alter the implementation or add new behaviour, there aren’t any recorded or manually mocked requests to update. Tests will depend on moto correctly mocking AWS services - but as a tradeoff, I think this is a worthwhile one.
With this in mind, let’s TDD a Lambda function, using moto and pytest for testing, and Serverless to get it deployed to AWS.
This post uses as its starting point the basic Lamdba setup created in the first post of this series, which can be downloaded here.. There are also links to the code at different points in this tutorial at the bottom of the post.
Getting Started
For the first time in this series, we’ll add some functionality to our Lambda function. I decided to replicate the common, if outdated, practice of reacting to files getting dropped to a folder. I’ve seen this pattern most notably in financial services, where an emitting service will drop files describing some desired (or already effected) transactions to an FTP server, and a second service picks up those files, processes them, and then moves them.
Let’s say the files will get uploaded to the incoming/ folder of an S3 bucket. We want our function to then be run, do some work, and move the incoming file to a processed/ directory in the bucket. We’ll build (and test!) the S3 functionality first, and then alter the function to implement some DynamoDB interactions as its “work”.
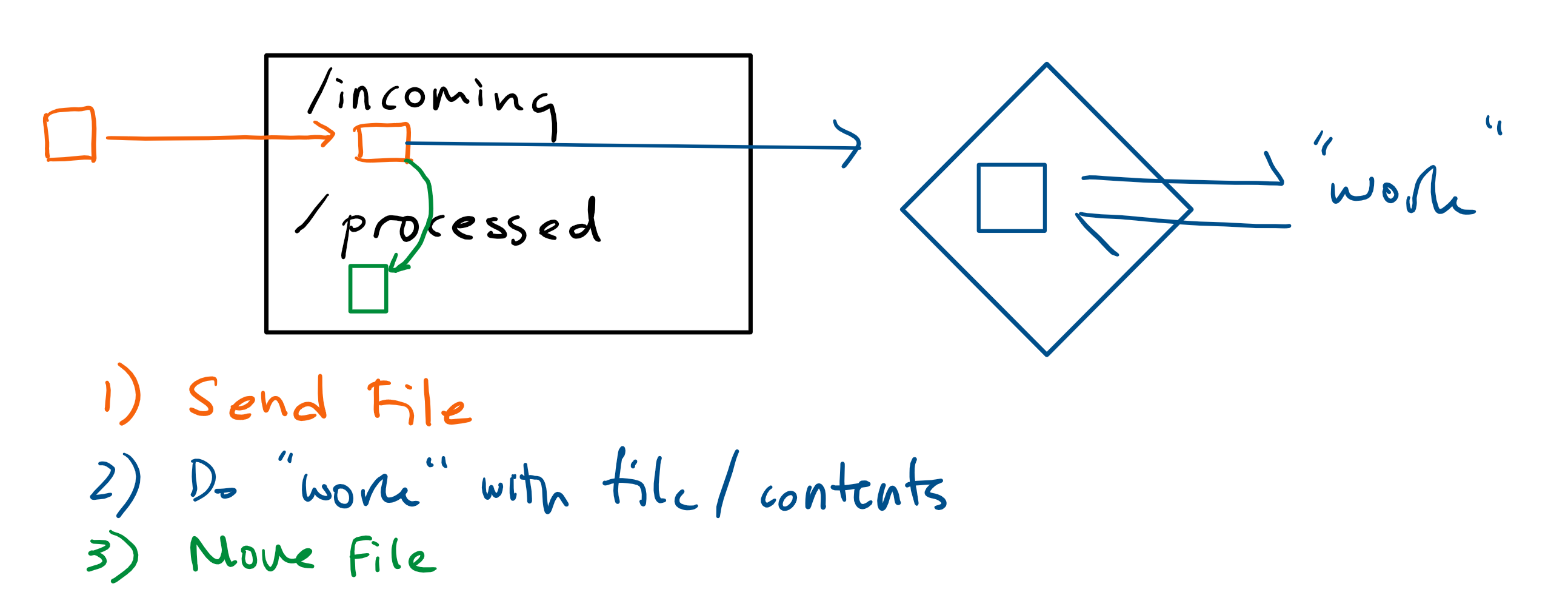
Right now our Lambda function, created in this previous post, does nothing. The project has just enough configuration to be deployable to AWS.
# handler.py
def call(event, context):
print("hello from handler!")
Adding a Test File
Let’s create a test file that we can use to test and develop our lamdba function. First, add pytest and moto to the requirements/requirements-dev.in file:
# in requirements/requirements-dev.in
-r requirements.in
moto==1.2.0
pytest==3.4.0
And then install them using pip
# If you haven't already done so, activate the virtualenv via `source .venv/bin/activate and ensure `pip-tools` are installed
$ pip-compile --output-file requirements/requirements-dev.txt requirements/requirements-dev.in
$ pip install -r requirements/requirements-dev.txt
With moto and pytest in place, we can create a new file, test_handler.py, for our tests:
# test_handler.py
import boto3
import pytest
from handler import call
## Test Setup Functions
def test_handler_moves_incoming_object_to_processed():
assert call(None, None) == None
A quick run of $ pytest test_handler.py will verify that our test framework is appropriately set up.
Testing S3 Interactions
Let’s update the test to check if the incoming file gets moved to processed. For our test setup, we’ll need to call moto’s mock_s3 method, create an S3 bucket and add a file to it. Then we can call the handler with a fake event saying that the file was created:
from botocore.exceptions import ClientError
from moto import mock_s3
def test_handler_moves_incoming_object_to_processed():
with mock_s3():
# Create the bucket
conn = boto3.resource('s3', region_name='us-east-1')
conn.create_bucket(Bucket="some-bucket")
# Add a file
boto3.client('s3', region_name='us-east-1').put_object(Bucket="some-bucket", Key="incoming/transaction-0001.txt", Body="Hello World!")
# Run call with an event describing the file:
call(s3_object_created_event("some-bucket", "incoming/transaction-0001.txt"), None)
We’re supposedly passing a fake S3 event to our handler, but we haven’t defined s3_object_created_event yet. Let’s define it now.
def s3_object_created_event(bucket_name, key):
# NOTE: truncated event object shown here
return {
"Records": [
{
"s3": {
"object": {
"key": key,
},
"bucket": {
"name": bucket_name,
},
},
}
]
}
Now the test setup is there. Let’s add assertions that the function moves the file from incoming/ to processed/:
def test_handler_moves_incoming_object_to_processed():
with mock_s3():
# ... (test setup)
#
# Assert the original file doesn't exist
with pytest.raises(ClientError) as e_info:
conn.Object("some-bucket", "incoming/transaction-0001.txt").get()
assert e_info.response['Error']['Code'] == 'NoSuchKey'
# Check that it exists in `processed/`
obj = conn.Object("some-bucket", "processed/transaction-0001.txt").get()
assert obj['Body'].read() == b'Hello World!'
A quick run of pytest test_handler.py will show the test is failing. We can update the function to make the test pass:
import boto3
import re
def move_object_to_processed(s3_client, original_bucket, original_key):
new_key = re.sub("incoming\/", "processed/", original_key)
s3_client.copy_object(
Bucket=original_bucket,
Key=new_key,
CopySource={'Bucket': original_bucket, 'Key': original_key}
)
s3_client.delete_object(Bucket=original_bucket, Key=original_key)
def call(event, context):
s3_client = boto3.client('s3')
record = event['Records'][0]
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
move_object_to_processed(s3_client, bucket, key)
Tada! We’ve now built our first set of functionality out with TDD. When we run our tests now, they’re passing - and no calls are made to AWS. That’s because moto is a stateful mock - it’s letting us make boto calls as we normally would, but it has removed any live calls to AWS. Additionally, it builds up state as you would normally expect with AWS - create a bucket, upload a file… from the perspective of subsequent boto calls in the test environment, these resources are actually there.
Let’s get it deployed before moving on to adding DynamoDB into the function.
Our First Deploy
We can update the serverless.yml file to include an S3 bucket & trigger.
We will need to add an S3 bucket to a new resources: section of the YAML file.
resources:
Resources:
S3BucketTestingLambdaFns:
Type: AWS::S3::Bucket
Properties:
BucketName: testing-lambda-fns-${opt:stage}
As a side note, I’ve named the bucket with the deployment stage as part of the name. This will enable Serverless to deploy our function with different buckets for staging and prod environments.
With this in place, we can define that our function should be triggered by ObjectCreated events in our S3 bucket. Note that serverless has us specify the bucket according to its logical ID - in this case S3BucketTestingLambdaFns becomes testingLambdaFns.
functions:
hello_world:
...
events:
- s3:
bucket: testingLambdaFns
event: s3:ObjectCreated:*
rules:
- prefix: incoming/
Finally, we need to add two permissions to the configuration: one to allow events from the S3 bucket to trigger our lambda function, and one to allow the function to make changes to objects in the bucket.
resources:
Resources:
...
HelloWorldLambdaPermissionTestingLambdaFns:
Type: "AWS::Lambda::Permission"
Properties:
FunctionName:
"Fn::GetAtt":
- HelloUnderscoreworldLambdaFunction
- Arn
Principal: "s3.amazonaws.com"
Action: "lambda:InvokeFunction"
SourceAccount:
Ref: AWS::AccountId
SourceArn: "arn:aws:s3:::testing-lambda-fns-${opt:stage}"
S3IamPolicy:
Type: AWS::IAM::Policy
DependsOn: S3BucketTestingLambdaFns
Properties:
PolicyName: lambda-s3
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:*
Resource: arn:aws:s3:::testing-lambda-fns-${opt:stage}/*
Roles:
- Ref: IamRoleLambdaExecution
That’s a little convoluted - and I don’t think there’s much skipping that with AWS - but at least we now have a deployable system. (I don’t have any shortcuts with AWS’s more complex sides - here’s a link to an open-source guide that’s pretty good, and there’s always AWS’s documentation..)
Go ahead and deploy it to your AWS account and test the function manually by uploading a transaction file to the incoming folder in the bucket. My test transaction file is a simple one-line file, and follows the naming convention transaction-0001.txt
$ serverless deploy --stage staging
Adding “Work”
So far, we’ve TDD’d our Lambda function and gotten it deployed, but it doesn’t do any “work” - it just moves incoming files to a different directory. Let’s say our “work” is to add an item to a DynamoDB table about the “transaction” the incoming file describes.
Just as we use mock_s3 to mock out S3, we will add a mock_dynamodb2 to mock out DynamoDB in the test environment. As a bit of cleanup before getting started, let’s move the test setup into its own method so we can write tests with a single with do_test_setup(): at the start.
BUCKET = "some-bucket"
KEY = "incoming/transaction-0001.txt"
BODY = "Hello World!"
## Test Setup Functions
from contextlib import contextmanager
@contextmanager
def do_test_setup():
with mock_s3():
set_up_s3()
yield
def set_up_s3():
conn = boto3.resource('s3', region_name='us-east-1')
conn.create_bucket(Bucket=BUCKET)
boto3.client('s3', region_name='us-east-1').put_object(Bucket=BUCKET, Key=KEY, Body=BODY)
Let’s add with mock_dynamodb2(): to the test setup:
from moto import mock_dynamodb2
...
def do_test_setup():
with mock_s3():
with mock_dynamodb2():
set_up_s3()
set_up_dynamodb()
yield
And set up a dynamodb table:
TXNS_TABLE = "my-transactions-table"
...
def set_up_dynamodb():
client = boto3.client('dynamodb', region_name='us-east-1')
client.create_table(
AttributeDefinitions=[
{
'AttributeName': 'transaction_id',
'AttributeType': 'N'
},
],
KeySchema=[
{
'AttributeName': 'transaction_id',
'KeyType': 'HASH'
}
],
TableName=TXNS_TABLE,
ProvisionedThroughput={
'ReadCapacityUnits': 1,
'WriteCapacityUnits': 1
}
)
Now we can test that our function is doing its work - adding an item to the database about the incoming transaction. Let’s just have it log the transaction ID and transaction file’s contents:
def test_handler_adds_record_in_dynamo_db_about_object():
with do_test_setup():
call(s3_object_created_event(BUCKET, KEY), None)
table = boto3.resource('dynamodb', region_name='us-east-1').Table(TXNS_TABLE)
item = table.get_item(Key={'transaction_id': '0001'})['Item']
assert item['body'] == 'Hello World!'
A quick run of pytest test_handler.py will reveal that the test is failing. Let’s add this functionality to the lambda function:
table = boto3.resource('dynamodb', region_name='us-east-1').Table("my-transactions-table")
txn_id = re.search("incoming\/transaction-(\d*).txt", key).group(1)
table.put_item(
Item={
'transaction_id': txn_id,
'body': s3_client.get_object(
Bucket=bucket,
Key=key
)['Body'].read().decode('utf-8')
}
)
The test now passes, and our lambda function is complete!
Deploying with Dynamodb
We’ll need two additions to the serverless.yml file to get this function deployed: one to create the DynamoDB table, and one to give the lambda function permission to use it:
resources:
# Add the DynamoDB table
DynamoDbTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: my-transactions-table
AttributeDefinitions:
- AttributeName: transaction_id
AttributeType: S
KeySchema:
- AttributeName: transaction_id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1
# Allow this function to access the table
DynamoDBIamPolicy:
Type: AWS::IAM::Policy
DependsOn: DynamoDbTable
Properties:
PolicyName: lambda-dynamodb
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- dynamodb:GetItem
- dynamodb:PutItem
Resource: arn:aws:dynamodb:*:*:table/my-transactions-table
Roles:
- Ref: IamRoleLambdaExecution
And that’s it! We now have a working Lambda function, complete with tests. A quick deploy to AWS will create the DynamoDB table and update our lambda function - go ahead and test the function manually and then check the table for an item about your transaction.
Conclusion & Considerations
As far as the original goal goes, I think the above outlines an effective way to test Lambda functions. The approach moto introduces will help to ensure changes to functions uphold the previously tested and implemented behaviour. I also found it to be a really useful way to guide learning. I previously hadn’t used DynamoDB. The code-level interactions with AWS were the same when mocked with moto, so learning how to write the test taught me about how to use DynamoDB as well.
I certainly wonder whether there’s a better (or “more Python”) way of doing things. I haven’t done much Python testing before, and chose pytest over nose and unittest because its test failures are well annotated. Coming from a background in Ruby and Elixir, I was looking for a way to pull my test setup neatly out of the test - I am not sure if the use of a context manager in do_test_setup is good or if there’s a better way.
Also, I’m still split on whether to use Serverless for provisioning infrastructure. Generally, I think for resources like S3 buckets and databases, it’s advisable to use other tools for this, such as terraform. That said, one plus from an all-Serverless setup is the simplicy in deploying (and removing) an entire service and its dependencies in one shot.
If you have any thoughts to add or approaches to share, I’m eager to hear. Leave a comment below!
Note: Here are some links to the code at different points in the tutorial: